
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 표본 공간
- 모드 붕괴
- stability-plasticity trade-off
- Autumation Tools
- GAN 손실함수
- 이중구조분해할당
- 자바스크립트
- 확률 변수
- Power Loss
- Django
- for-of
- 생산적 적대 신경망
- 생성AI
- catastrophic forgetting
- javascript
- fine grained
- python
- 인공지능 학회
- javacript
- 인프런
- 앱 구조
- application structure
- 장고
- Voltage Drop
- 훈훈한 Javascript
- 설계철학
- zero-shot
- multi-label
- few-shot
- GAN 이해
- Today
- Total
점점 미쳐가는 개발 일기
Computer Vision Major Task List - (2): Object Detection 본문
Computer Vision Major Task List - (2): Object Detection
Sangwoo Seo 2023. 9. 7. 13:56지난 글 :
Computer Vision Major Task List - (1): Image Classification | https://sawoo9410.tistory.com/23
2. Object Detection
지난 글에 이어 컴퓨터 비전 분야의 주요 task 중 하나인 'Object Detection'에 대해 소개하려 합니다. 이 task는 분류(classification) 문제와 위치 탐색(localization) 문제를 동시에 해결하려는 아이디어에서 출발하였습니다.
분류(Classification): 이미지나 비디오에서 감지된 각 객체가 어떤 클래스에 속하는지 결정합니다. 예를 들어, 개, 고양이, 사람, 자동차 등을 분류할 수 있습니다.
위치 탐색(Localization): 객체의 정확한 위치를 결정하며, 이는 일반적으로 경계 상자(Bounding Box) 형태로 표현됩니다. 즉, 이미지에서 객체가 차지하는 영역을 사각형으로 나타냅니다.
객체 탐지는 이 두 작업을 동시에 수행하여, 이미지 안의 각 객체를 분류하고 위치를 파악합니다. 이렇게 하면 이미지에서 개체를 식별하고, 그 위치를 파악하며, 동시에 해당 개체의 클래스 또한 결정할 수 있습니다. 이런 기능 덕분에 객체 탐지는 많은 실용적인 응용 사례를 가지고 있습니다. 예를 들어, 도로에서 주행하는 자동차의 경우, 사람이나 다른 차량, 신호등 등 다양한 객체를 정확하게 인식하고 그 위치를 파악하는 것이 중요합니다. 객체 탐지는 이러한 과제를 해결하기 위한 핵심 기술이며, 자율주행 자동차, CCTV 분석 등 다양한 분야에서 활용되고 있습니다.
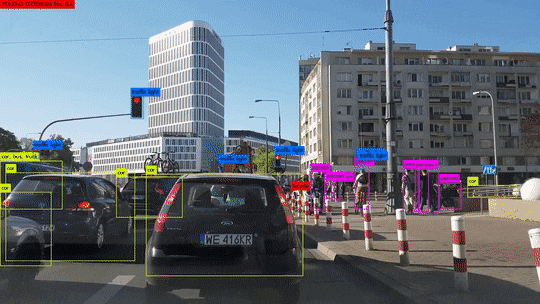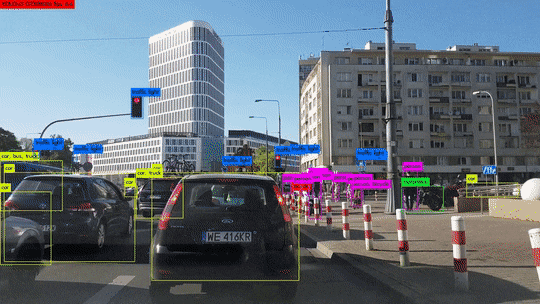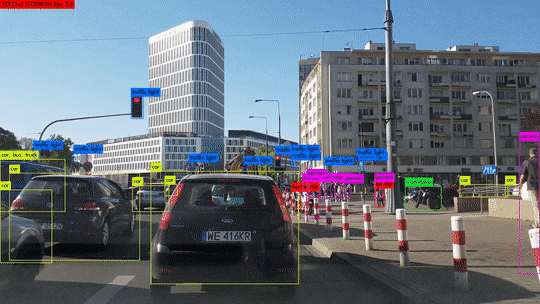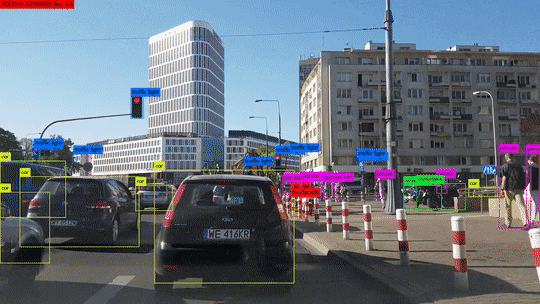
객체 탐지는 분류 문제와 위치 탐색 문제를 해결하는 방식에 따라 1-stage detection 방식과 2-stage detection 방식이 있습니다.
1-stage detection은 이름에서 알 수 있듯이, 이미지를 한 번만 보고 분류와 위치 탐색을 동시에 수행합니다. 이는 전체 이미지를 고정된 수의 그리드로 분할하고, 각 그리드 셀에 대해 바운딩 박스를 예측하며, 동시에 그 박스에 있는 객체가 어떤 클래스에 속하는지 분류합니다. 이 방식은 처리 속도가 빠르다는 장점이 있지만, 비교적 정확도가 낮다는 단점이 있습니다. 대표적인 알고리즘은 YOLO(You Only Look Once)나 SSD(Single Shot MultiBox Detector)가 있습니다.
2-stage detection은 먼저 이미지에서 관심 영역(Region of Interest, RoI)을 추출하고(이를 '관심 영역 제안(RoI proposal)' 단계라고 부르기도 합니다), 그 후 각 RoI에 대해 분류와 위치 탐색을 수행합니다. 이 방식은 두 단계를 거치기 때문에 '2-stage detection'이라 부릅니다. 이 방식은 비교적 높은 정확도를 제공하지만, 복잡한 계산으로 인해 처리 속도가 느린 편입니다. 대표적인 알고리즘은 R-CNN(Regions with CNN features)과 후속 모델인 Fast R-CNN, Faster R-CNN이 있습니다.
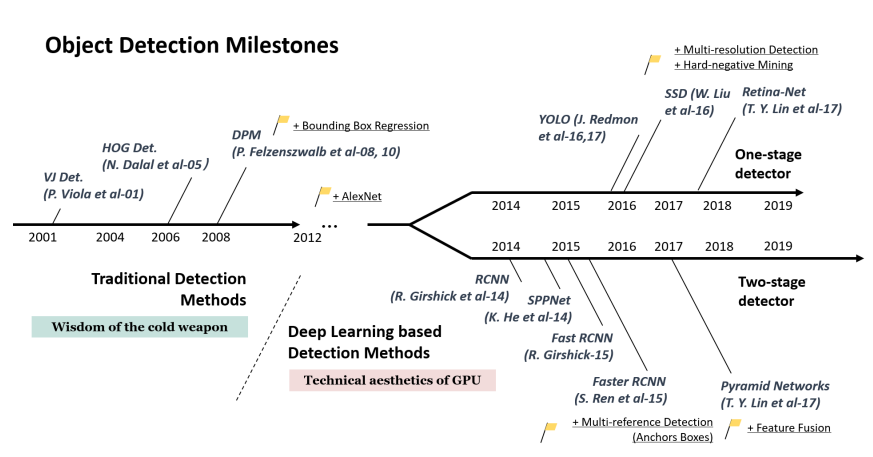
대표적인 알고리즘: YOLO, R-CNN, SSD
Paper with code: https://paperswithcode.com/task/object-detection
Object Detection' advanced task
• Object Tracking
Object tracking(이하 객체 추적)은 동영상(즉, 연속적인 이미지 프레임)에서 객체의 움직임을 추적하는 task입니다. 여기서는 객체가 프레임 간에 어떻게 움직이는지를 파악해야 합니다. 객체 추적의 기본적인 프로세스는 초기 프레임에서 추적하려는 대상의 위치를 지정하고, 이후의 프레임에서 이 객체의 움직임을 추적하는 것입니다. 이 과정은 각각의 연속적인 비디오 프레임에서 객체의 위치를 예측하고, 이 예측된 위치를 기반으로 실제 위치를 찾아내는 작업을 포함합니다. 이때 이 예측과 검출의 과정은 추적 알고리즘에 따라 다르게 이루어질 수 있습니다. 객체 추적은 보통 CCTV, 자율 주행, 비디오 분석, 컴퓨터 비전 등의 분야에서 사용되며, 보통 객체 탐지와 결합하여 사용됩니다.
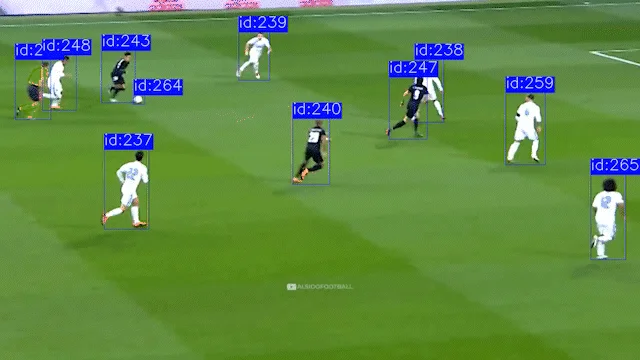
대표적인 알고리즘: Kalman Filtering, MeanShift/CamShift, Optical Flow, SORT, DeepSORT
Paper with code: https://paperswithcode.com/task/object-tracking
• 3D Object Detection
3차원 데이터(예: Lidar 또는 스테레오 이미지)에서 객체를 감지하는 태스크입니다. 이는 주로 자율주행 자동차에서 사용되며, 객체의 위치뿐만 아니라 깊이 정보도 동시에 파악해야 합니다.
3D 객체 감지는 컴퓨터 비전의 중요한 주제로, Lidar, 레이더, 스테레오 이미지 등과 같은 3차원 데이터로부터 객체를 감지하고 위치를 파악하는 것을 목표로 합니다. 이는 전통적인 2D 객체 감지와 달리, 객체의 높이, 너비, 깊이를 고려하여 객체의 3차원 형상과 위치를 정확하게 추정합니다.
이 기술은 주로 자율주행 자동차와 로보틱스 분야에서 사용되며, 이들 시스템이 주변 환경을 더 정확하게 이해하고 안전하게 움직일 수 있도록 돕습니다. 예를 들어, 자율주행 자동차에서는 Lidar와 같은 센서를 사용하여 차량 주변의 다른 객체를 감지하고 그들의 위치와 속도를 파악하는 데 이를 활용합니다.
3D 객체 감지 알고리즘은 주로 지도학습 방법을 사용하며, 딥러닝 기반의 방법이 많이 활용되고 있습니다. 학습 데이터는 3D point cloud나 스테레오 이미지에 객체의 3D 경계 상자(bounding box)가 표시된 형태로 제공됩니다.

대표적인 알고리즘: PointRCNN, 3DOP, MV3D
Paper with code: https://paperswithcode.com/task/3d-object-detection
• Object Counting
객체 세기(Object Counting)는 컴퓨터 비전의 중요한 작업 중 하나로, 이미지 또는 비디오에서 특정 클래스의 객체 수를 세는 것을 목표로 합니다. 예를 들어, 사람, 자동차, 나무 등 특정 객체의 수를 파악하는 것이 필요한 다양한 상황에서 사용됩니다.
이 작업은 보행자 흐름 분석, 교통 관리, 도시 계획, 생태학 연구 등 다양한 분야에서 중요한 역할을 합니다. 예를 들어, 보행자 흐름 분석에서는 보행자 수를 계산하여 시설 용량이나 이벤트 효과를 평가할 수 있습니다. 교통 관리에서는 차량 수를 계산하여 교통 흐름을 분석하고, 교통 혼잡을 예방하는 데 도움이 됩니다.
하지만, 이 작업은 간단해 보일 수 있지만 실제로는 많은 어려움이 있습니다. 객체들이 겹치거나 서로를 가리거나, 다양한 크기와 모양을 가질 때 객체를 정확하게 분리하고 세는 것은 어려운 문제입니다. 이러한 문제를 해결하기 위해 많은 알고리즘이 제안되었으며, 이 중 대부분은 이미지 처리 기법과 머신 러닝, 딥 러닝을 활용하고 있습니다.
일부 방법론은 먼저 객체 검출(object detection)을 수행하여 각 객체를 분리하고 이를 세는 방법을 사용합니다. 다른 방법론은 객체의 밀도를 예측하고, 이를 사용하여 전체 객체 수를 추정하는 방법을 사용합니다. 이런 방법들은 각각의 장단점을 가지며, 특정 상황에 따라 적합한 방법을 선택하는 것이 중요합니다.
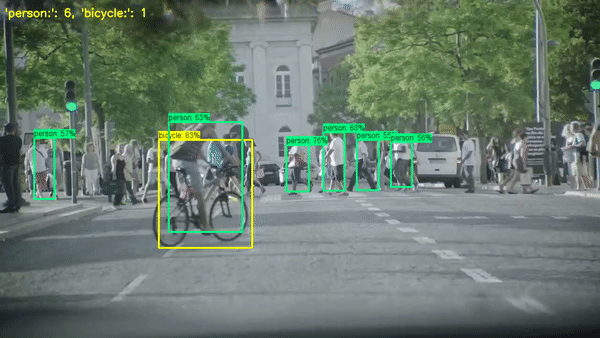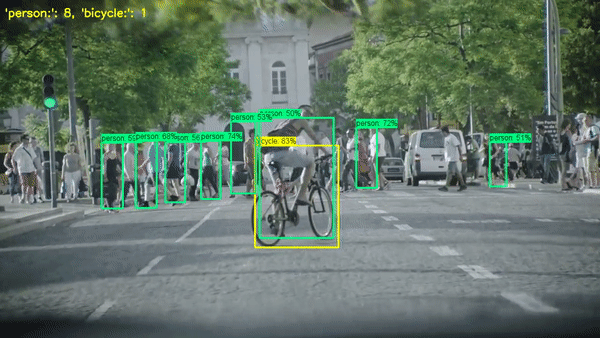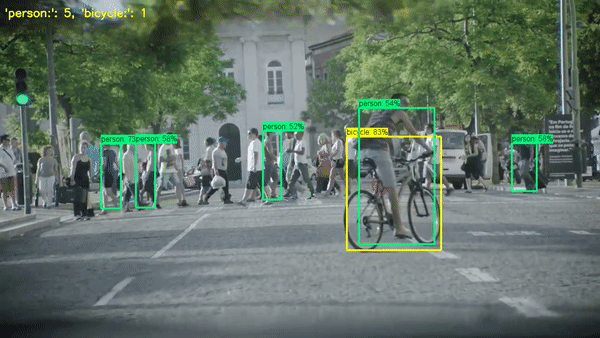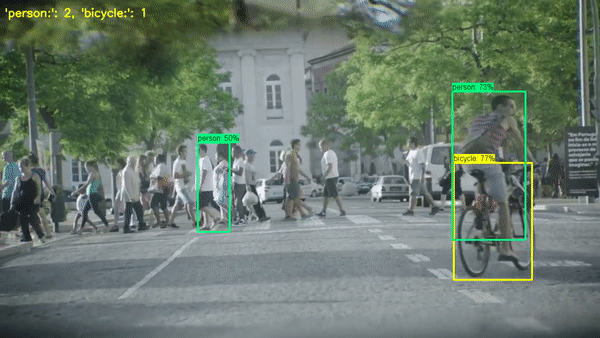
Paper with code: https://paperswithcode.com/task/object-counting/codeless
• Zero-Shot Learning for Object Detection
Zero-Shot Learning for Object Detection(ZSL을 이용한 객체 탐지)은 훈련 데이터에 없는 새로운 클래스의 객체를 탐지하는 과정입니다. 이전 글에서 설명 드렸듯이 ZSL은 모델이 학습 과정에서 본 적 없는 새로운 클래스에 대해 예측을 수행하도록 설계된 기계 학습의 한 가지 방법입니다. ZSL은 일반적으로 객체를 분류하거나 탐지하는 모델을 훈련할 때 사용됩니다. 이 경우 모델은 학습 단계에서 사용되지 않은 새로운 클래스의 객체를 탐지할 수 있어야 합니다. ZSL은 그러한 클래스를 탐지하는 능력을 향상시키기 위해 일반적으로 semantic embedding이나 속성 정보 같은 보조 정보를 활용합니다.
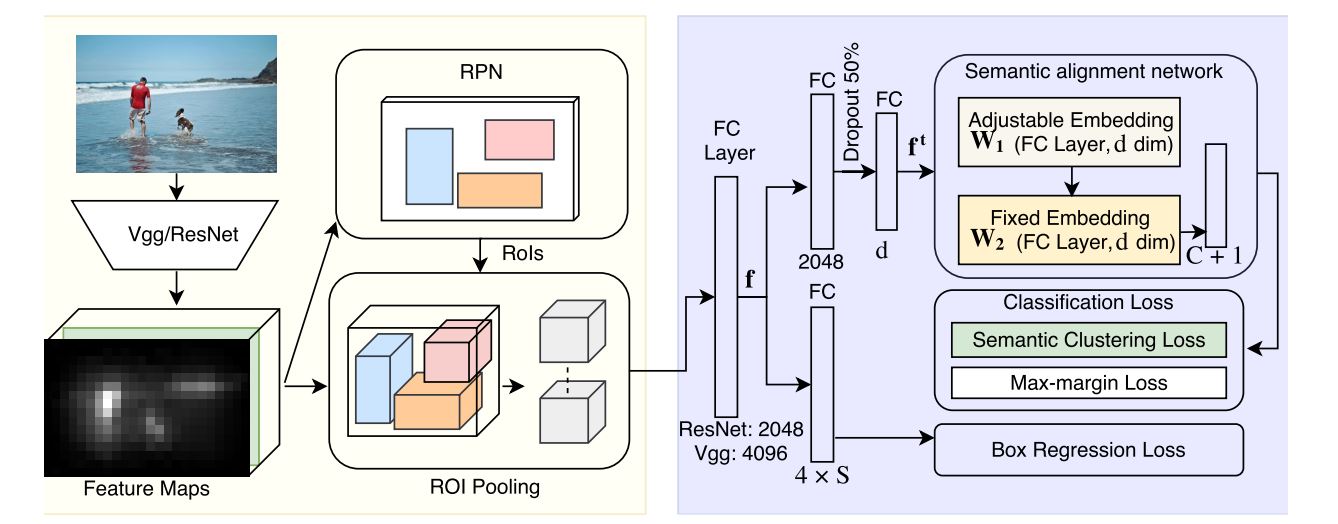
반면에, 의미론적 분할(Semantic Segmentation)은 이미지의 각 픽셀이 어떤 클래스에 속하는지를 판단하는 이미지 분석의 한 분야입니다. 이는 객체를 구분하는 것을 넘어서 이미지의 모든 픽셀에 레이블을 할당함으로써, 이미지 내의 객체를 더욱 정밀하게 이해하는데 도움이 됩니다.
의미론적 분할을 사용하면 이미지에서 객체의 정확한 위치, 모양, 크기를 파악할 수 있습니다. 이는 고유한 픽셀 수준에서 각 객체를 식별함으로써, 보행자, 자동차, 도로, 건물 등의 서로 다른 객체들을 이미지에서 정확하게 분리하고 식별할 수 있습니다. 이러한 기능은 도시의 풍경을 분석하거나 자율 주행 자동차에게 주변 환경을 이해하는 데 매우 중요합니다.
따라서, 제로샷 학습과 의미론적 분할은 서로 보완적인 방식으로 작동하여, 복잡한 시각적 환경에서 미처 학습되지 않은 새로운 클래스를 식별하고, 이미지 내의 객체를 정밀하게 분리하고 분류하는데 도움을 줄 수 있습니다. 이 두 가지 방법 모두 컴퓨터 비전의 핵심적인 작업이며, 자율주행, 로봇공학, 보안 등의 분야에서 널리 사용되고 있습니다.
Paper with code: https://paperswithcode.com/task/zero-shot-object-detection
'인공지능 > Computer Vision(CV)' 카테고리의 다른 글
| Computer Vision Major Task List - (1): Image Classification (0) | 2023.07.20 |
|---|---|
| GAN(Generative Adversarial Networks) 이해하기 (0) | 2023.06.30 |

